


Introduction
In the modern digital era, data is the lifeblood of organizations, flowing from diverse sources and formats. Managing, integrating, and transforming this data efficiently is critical for gaining actionable insights. Microsoft’s Azure Data Factory (ADF) is a cloud-native, fully managed data integration service designed to simplify these complex data workflows. This blog offers an in-depth exploration of ADF, its architecture, key features, and practical examples to illustrate how it makes data integration seamless and scalable.
What is Azure Data Factory?

Azure Data Factory is a serverless data integration platform that enables you to create, schedule, and orchestrate data pipelines for moving and transforming data at scale. It supports over 90 built-in connectors to a wide variety of data sources—from traditional databases like SQL Server and Oracle to cloud storages like Azure Blob, AWS S3, and SaaS applications such as Salesforce and SAP.
ADF abstracts the complexity of data engineering by offering a low-code/no-code visual interface, enabling both developers and business users to build end-to-end data workflows without deep coding expertise. It integrates seamlessly with Azure analytics services like Azure Synapse Analytics, Azure Databricks, and HDInsight, empowering advanced data transformation and analytics
Core Components of Azure Data Factory
Understanding ADF’s architecture is key to leveraging its full potential. The main components include:
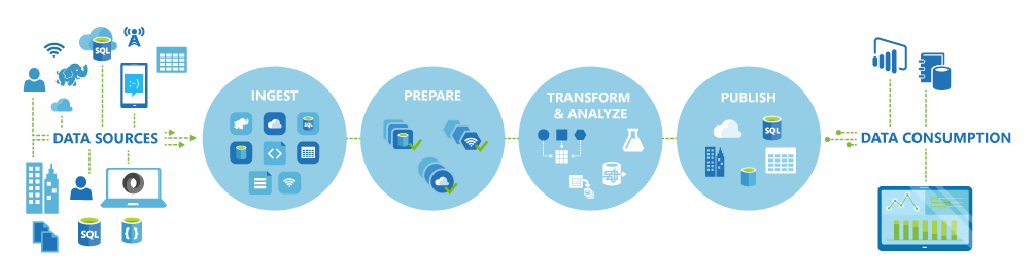
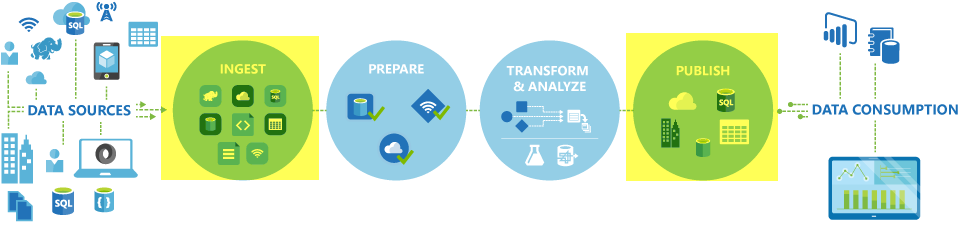
Image - Azure Data Factory focuses on Data Ingestion
How Azure Data Factory Works: The Data Pipeline Lifecycle
A typical ADF pipeline involves three key phases:
- Connect and Collect: Using linked services and datasets, ADF connects to various data sources—whether on-premises or cloud-based—and ingests data using the Copy activity. For example, moving transactional data from an on-prem SQL Server to Azure Blob Storage
- Transform and Enrich: Once data is centralized, ADF leverages Mapping Data Flows or custom code (Python, SQL, Spark) to cleanse, aggregate, and enrich the data. This can include filtering anomalies, joining datasets, or applying business rules
- Publish and Deliver: The transformed data is then loaded into target systems such as Azure Synapse Analytics, Azure SQL Database, or data lakes, ready for consumption by BI tools or machine learning models
Key Features That Make Data Integration Easy
- Extensive Connectivity: With over 90 connectors, ADF supports databases (SQL Server, MySQL, PostgreSQL, Oracle), cloud storage (Azure Blob, AWS S3, Google Cloud Storage), SaaS apps (Salesforce, Dynamics 365), and big data platforms like Hadoop and Spark
- Low-Code Authoring: The drag-and-drop interface and prebuilt templates allow users to build pipelines without writing extensive code. This speeds up development and reduces errors
- Flexible Scheduling and Triggers: Pipelines can be triggered by schedules (hourly, daily), events (file arrival), or manually, enabling automation of complex workflows
- Error Handling and Monitoring: ADF provides built-in retry mechanisms, alerting, and visual monitoring dashboards within the Azure Portal. Integration with Azure Monitor offers deeper insights and logging
- Security and Governance: Role-Based Access Control (RBAC) ensures secure access. Integration with Microsoft Purview enables data cataloging and governance for compliance
- Scalability and Cost Efficiency: Being cloud-native, ADF auto-scales based on workload and follows a pay-as-you-go pricing model, eliminating upfront infrastructure costs
Practical Examples of Azure Data Factory Use Cases
- Example 1: Hybrid Data Migration A healthcare provider needs to migrate patient records from an on-premises Oracle database to Azure SQL Database for analytics. Using ADF’s Self-hosted Integration Runtime, the provider builds a pipeline that securely copies data nightly. Data flows then anonymize sensitive fields before loading into the cloud warehouse, ensuring compliance with privacy regulations.
- Example 2: Multi-Source Data Aggregation A retail chain aggregates sales data from Salesforce CRM, Azure Blob Storage, and an on-premises MySQL database. ADF pipelines ingest data from these sources, and Mapping Data Flows perform deduplication, currency conversion, and customer segmentation. The processed data is loaded into Azure Synapse Analytics for real-time dashboards.
- Example 3: Event-Driven IoT Data Processing An energy company collects sensor data uploaded hourly to Azure Blob Storage. An event trigger in ADF detects new files, launching a pipeline that filters out erroneous readings and enriches data with weather information via REST API calls. The clean data is stored in Azure Data Lake for downstream machine learning.
- Example 4: End-to-End Data Integration Tutorial (NYC Taxi Data) Microsoft’s official tutorial demonstrates an end-to-end pipeline where raw taxi trip data is ingested from blob storage into a bronze data layer, transformed in a dataflow to a gold data layer, and finally, an email notification is sent upon completion. This showcases ingestion, transformation, and orchestration capabilities in a real-world scenario.
Advanced Topics and Best Practices
- Integration with Azure Databricks and Synapse: For complex transformations beyond Mapping Data Flows, ADF pipelines can orchestrate Databricks notebooks or Synapse Spark jobs, combining ETL with advanced analytics
- Data Observability: Tools like Kensu integrate with ADF to provide data lineage, schema change detection, and quality metrics, helping data teams proactively manage pipeline health and reliability
- Medallion Architecture Support: ADF supports modern lakehouse patterns, enabling staged data layers (bronze, silver, gold) for incremental refinement and governance
- Cost Optimization: Use pipeline triggers wisely to avoid unnecessary runs, leverage data partitioning, and monitor pipeline performance to optimize resource usage and costs
Outcome of my Blog
Whether you are migrating legacy systems, building real-time analytics pipelines, or orchestrating complex data workflows, ADF provides the tools and flexibility to make data integration truly easy and efficient.
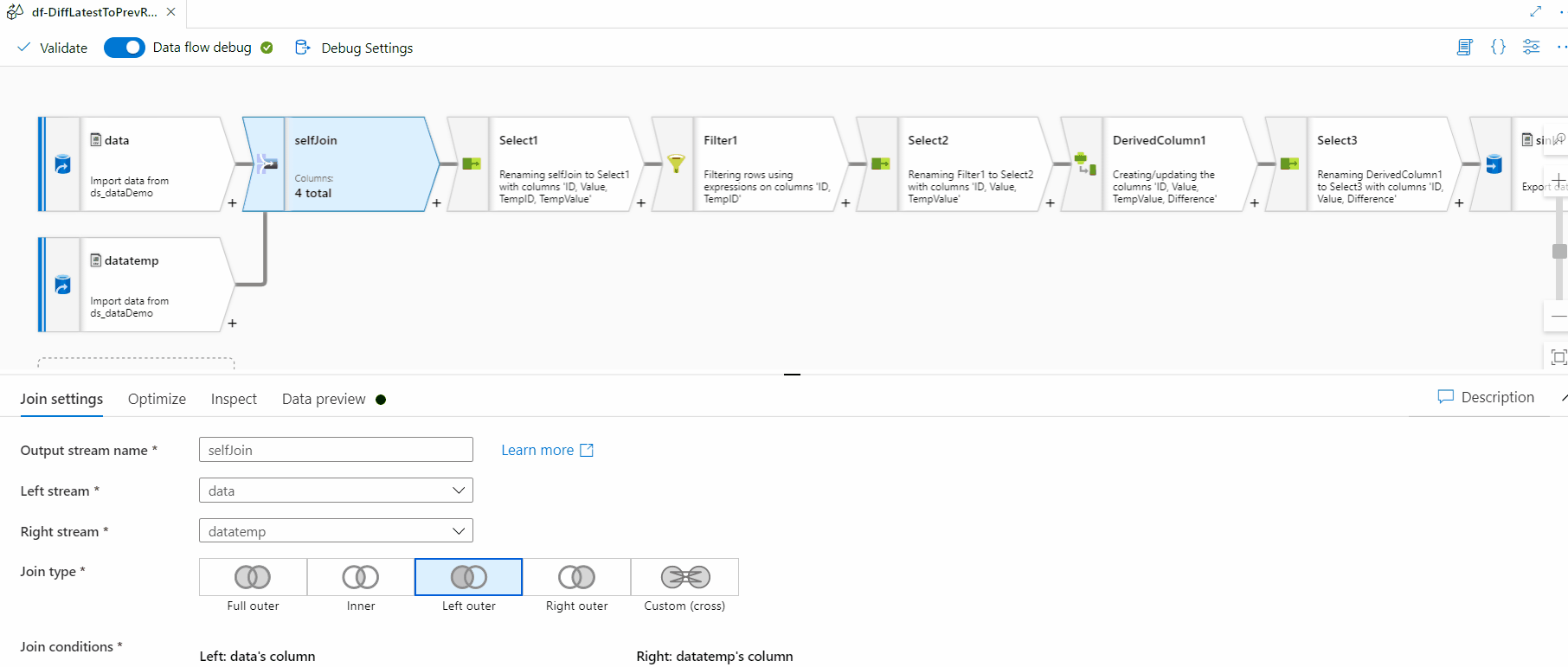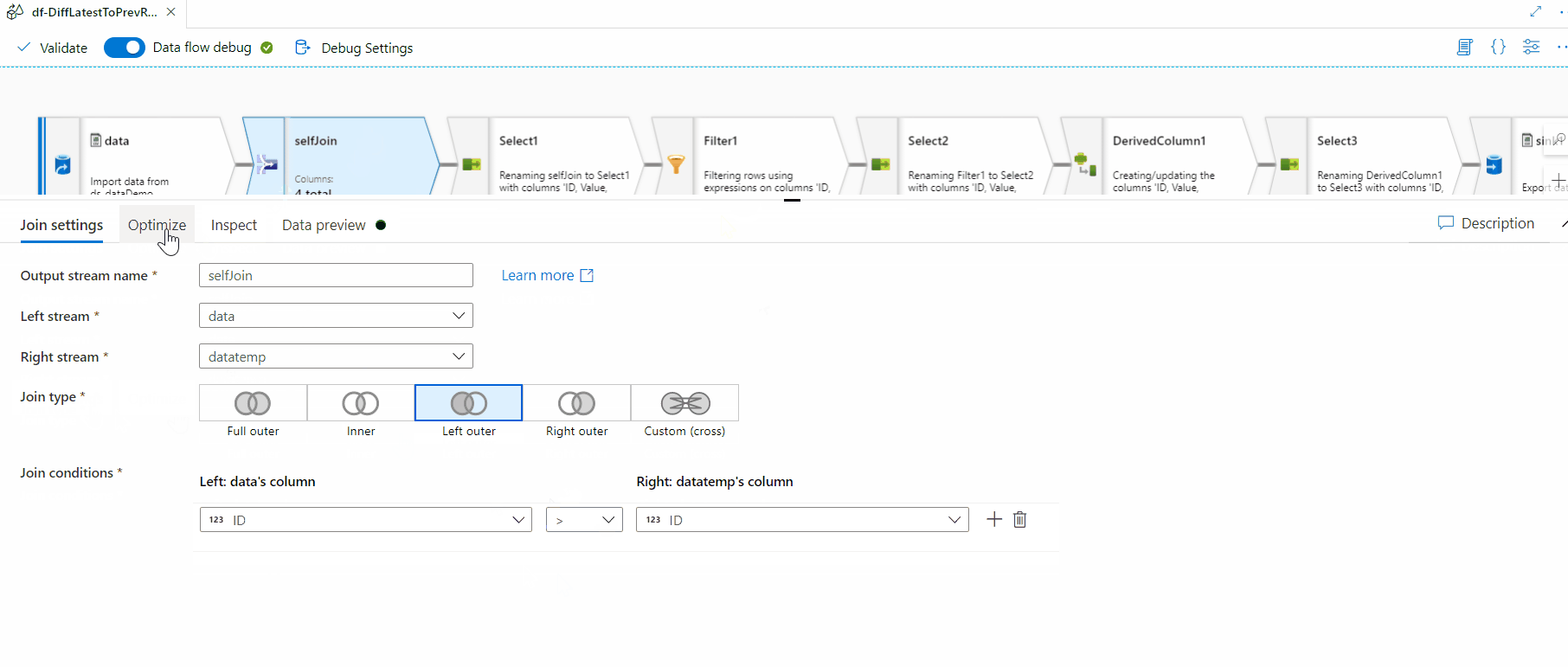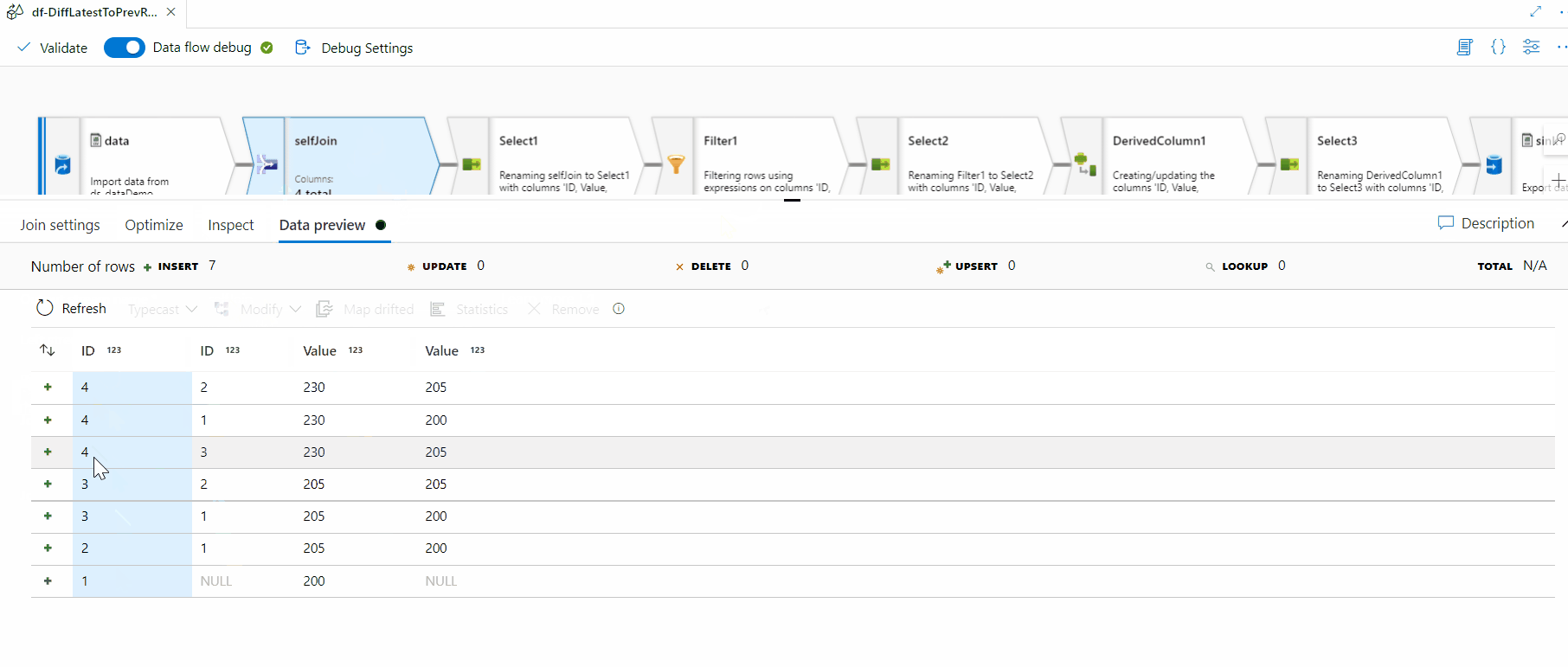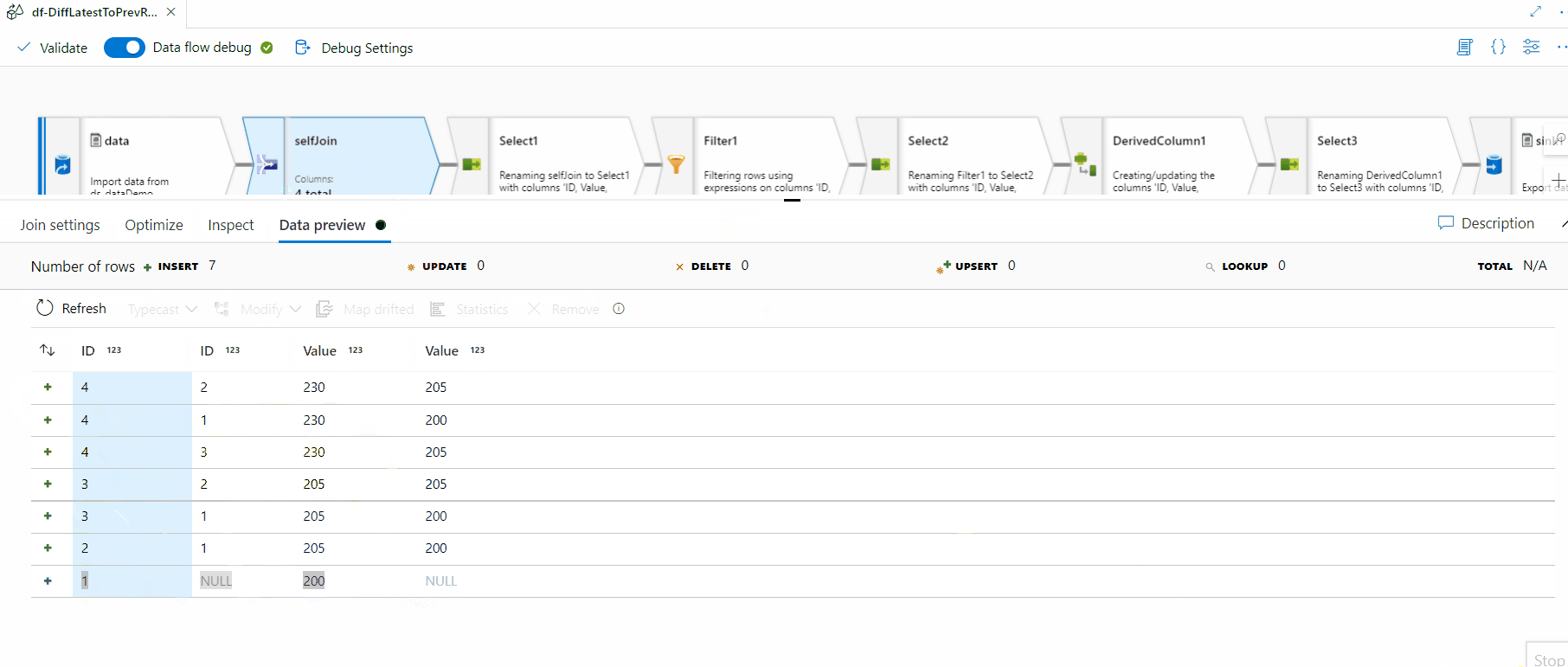
Image - ETL Job
